
Handbook of Software for Engineers and Scientists
Chapter 14 – C++ and Objective C
excerpt notice
2.0 The C++ Language
C++ is an immensely rich language. This richness is both a blessing and a curse. A blessing, because of the expressive power and support for several programming paradigms; a curse because this richness means complexity, and there is much to master. C++ is a language to grow with, one for which each experience can teach new features, or better understanding.
Since each of C++'s features may interact with the others, learning C++ feels like gradually filling in a not-so-sparse matrix of knowledge formed by the cross product of the C++ feature vector with itself. No serious use of the language should be undertaken without good references at hand. The end of this section has several suggestions for more complete sources of C++ knowledge, along with brief commentary on the strengths of each reference.
C++ was developed by Bjarne Stroustrup at Bell Laboratories in the 1980s for his own use in writing complex simulations [Stroustrup, 1991]. His stated design goals for the language were:
- to improve upon C,
- to better support data abstraction,
- and to support object-oriented programming.
In addition to these goals, compatibility with C was to be maintained, and C's applicability to demanding low-level system programming problems retained. The support for object-oriented programming was inspired by Simula67.
In 1989 interest in C++ was sufficiently wide-spread to warrant the initiation of an ANSI/ISO standardization effort. The ANSI X3J16 committee is expected to issue the first C++ language standard by the end of 1996. Until that time, the de facto standard for the language is the ANSI committee baseline document, The Annotated C++ Reference Manual by Ellis and Stroustrup [Ellis, 1990], known as the "ARM".
The original C++ “compiler" was actually a translator which pre-processed C++ into plain C, and compiled the result. The cfront translator is currently in Release 3.0. Many other C++ compilers are now available, including the free (via the Internet) GNU C++ compiler from the Free Software Foundation, which has been ported to many architectures and operating systems. The portability of C++ code between compilers tends to depend on the usage of recent, or advanced, features of the language. The more of these features used, the less likely the code will be portable across many compilers. In general, C++ is more portable between the many UNIX-based compilers than it is from one of the UNIX-based compilers to a DOS/Windows-based compiler.
As planned, ANSI C is nearly a perfect subset of C++. Most ANSI C programs will compile without change using a C++ compiler. Books such as [Lippman, 1991], or [Stroustrup, 1991] describe the few areas in which C++ and ANSI C differ. Older Kernighan and Ritchie (K&R) C programs require a little more work, chiefly in the area of function declarations.
2.1 Improvements over ANSI C
The features described in this section represent those which were added to C++ to improve on some aspect of the C language. Many of them answer criticisms of C (e.g. weak type checking, syntax for pass-by-reference parameters) and others were included to improve the representation and use of abstract data types. The features described here represent the most important non-object-oriented extensions which C++ adds to ANSI C, and are loosely classified into five groups: comments, types and declarations, functions, memory management, and I/O.
2.1.1 Comments
The traditional C comment delimiters ( /* and */ ) have been supplemented with a new, to-the-end-of-line delimiter, the double-slash, //. One major advantage of the new style comment is that they may be nested, whereas the old-style may not. The three examples below show typical uses of C++ comments. The third code fragment shows a use for the new style which could not be achieved with the old style alone.
2.1.2 Types and Variable Declarations
The names of structures are types, so that the keyword struct may be be omitted in the definition or declaration of structures, or when describing structures as parameters. This eliminates the need for typedefs in many situations.
Automatic (i.e. local) variables may now be defined anywhere in blocks, rather than strictly at the top of the function. This allows for variables to be defined at their point of use, rather than at the top of the function, potentially well before their actual use.
A new type modifier, const, allows for truly constant-valued variables, rather than having to use the pre-processor to this effect.
Variables which are defined const must be initialized, since they may not be assigned to. The compiler will enforce the meaning of the constant modifier. This is different than a #define macro "constant", since the const variable is a real variable, with space allocated for it by the compiler.
C++ provides an alternative to the type cast means of converting from one type to another. A data type may be applied to a variable with a function-like syntax:
C++ supports anonymous unions (unions without names). This reduces the level of access operators that must be applied to access an element of a structure containing a union.
2.1.3 Functions
Many improvements were made in the support for functions. The first, and arguably the most important, is the improved type checking of function parameters and return values. This improvement is shared by ANSI C, but is important enough to describe here. Old style C allowed for use of a function before its definition. The compiler assumed the return value of the function was an integer, and did not attempt to check whether the function was invoked with the correct number and type of parameters.
In C++, the compiler must be given a prototype declaration of a function before it is used. The function prototype consists of three things: the name of the function, the type of the return value, and the type of each parameter. Function prototypes are usually placed in header files which are #include'd by the source file where the function is used. With the information from the prototype, the compiler can check each function invocation to see if the parameters are of the proper type and number, and if the return value is stored into a variable of the proper type. Function prototypes must agree with the definition of the function. The actual names (but not the types) of the parameters are optional in a prototype.
C++ allows for the overloading of function names. This means that more than one function may have the same name, as long as the compiler can distinguish the like-named functions by their return type and parameter list. For example, ANSI C would require three different names for three functions which printed variables of different types.
But C++ allows a single name to be overloaded, and used for each of these functions. The compiler knows which function is being invoked by the type of the parameter being passed.
Default parameters allow for the invocation of functions with no values for those parameters which have defaults. Default values are specified for parameters in the function declaration. A parameter can only have its default value specified once in any given file. The header file which contains the function prototype is preferred for default values over the function definition.
float washerArea(float id = 0.5, float od = 1.0);washerArea(); // area of 1/2" washerwasherArea(0.2); // area of "fat" washerwasherArea(0.75, 1.5); // area of 3/4" washer
The positional matching of values with parameters restricts which parameters may be allowed to default. Every parameter to the right of the first default-value parameter must also default. In the example above, there is no way to specify a function invocation of washerArea which has a default value for od, but not id.
A notation for denoting that a function takes an unknown number of unknown type parameters is available in C++. The classic example for the need for such a notation (previously done with the C pre-processor in varargs.h) is the function printf. After the first argument to printf (a char * format string), the number and type of the arguments depends on the specific use of the function. In C++ we could declare the printf function like this:
The ellipsis turns off the argument checking normally done by the compiler.
Function parameters in C are passed by value. In order to have another function operate on a variable local to the scope where the function is invoked, the address of the local variable is passed to the function. This is a common use of the pointer in C. For example,
The disadvantage of passing addresses as parameters to the function enterProcessInfo is that it requires us to use a different syntax to access these parameters in the function. The de-referencing operators -> and * must be used to read or write the parameters. We also must use the & operator in the function invocation in order to send the address of our data objects, and not their value.
C++ has another means of passing a parameter by reference. Reference parameters to functions may be treated in the function as a "normal" variable, i.e. no de-referencing operators are necessary. In addition, the address of variables is automatically passed at invocation, so the & operator is also unnecessary. With the reference parameter, we could re-write the above code fragment to:
Reference variables may also be used, like pointers, to create another name for a data object:
Reference variables must be initialized to the address of a variable of compatible type. Their referent cannot be changed at run-time.
In terms of the output of the compilation process (an executable program file), the use of functions to organize and re-use code represents a tradeoff between space and time. By having multiple function invocations to the same code, the size of the program is reduced, as the code for the function isn't replicated at the point of each use of that function. There is a cost in time, since the passing of parameters, and the change of control flow takes some time for the CPU to perform. The presence of an instruction cache, and a heavily pipelined CPU tend to make this cost relatively greater on high performance computers. C++ provides a means of controlling the tradeoff between time and space more precisely. By declaring a function with the keyword inline, the compiler will replace the usual assembly language code to jump to the function with the actual code of the function.
By putting the actual function code inline with its invocation, the size of the program is increased, but the program will execute faster. For very small functions, both code size and time may be saved. The inline specifier is only a hint to the compiler. The compiler gets to decide whether the function can be "inlined" at each point of invocation (it may be too complex, or the circumstances may not allow it). Novice C++ programmers inline too readily. Inlining should only be considered after careful performance analysis of the program under execution.
2.1.4 Memory Management
C++ offers a new model of memory management to replace C's malloc and free. The operators new and delete allocate and release memory from the free store. Memory allocated by new will be available to the programmer until it is returned to the free store with delete. See the earlier discussion on object lifecycle issues for more information on this important subject. The example below is typical of the use of new; a node in a tree is being dynamically allocated then released.
The function newNode dynamically allocates a node by calling new. The new operator returns a pointer to the newly available memory. The function returns this pointer so that the new TreeNode structure object can be used elsewhere in the program. Eventually, when the program no longer needs this TreeNode object, the delete operator is called with the address of the TreeNode structure. This returns the memory to the free store.
The new and delete operator have a slightly different syntax for allocating arrays of objects.
It is important that you use the delete [] operator when you are deleting something that was allocated with new [] (a vector), and use delete when you are deleting something that was allocated with new (a scalar).
The malloc/free facility is still available, though new and delete are preferred. Mixing the two facilities in the same program is dangerous.
2.1.5 Input and Output
The standard input/output facility of C continues to work in C++. An improved facility, known as iostream, takes advantage of the improved support for data abstraction and operator overloading. To fully understand the iostream facility requires knowledge of the class concept. This issue is revisited in more detail later in this section.
The standard input of a C++ program is reached via the object cin. Similarly, the standard output is available at cout. The operators << and >> are overloaded to work with cin and cout and produce formatted input and output. Consider the classic "hello, world" program in C++:
The << operator may be chained with other << operators, so that
Is equivalent to
And neither output line will be flushed to the standard output until either
or
is performed. The corresponding input operator, >> works with cout to read the standard input. Notice the use of the reference operator in the input function below.
The standard error is available to C++ programs as cerr.
2.1.6 Advice for C Programmers
The following advice for C programmers converting to C++ was gleaned from Stroustrup, Lippman, and Meyers.
- convert #define macros to const data types, or inline functions
- use the const modifier whenever possible
- prefer C++ style comments (//) over C style comments (/* */)
- use the iostream library, rather than stdio
- define variables where they are first used, rather than at the top of a function
- use new and delete, not malloc and free
- use the improved data abstraction and OO features of C++ to avoid void*, pointer arithmetic, arrays, and type casts
- think in terms of objects messaging each other, rather than data structures operated on by functions
C++ code may be linked with C code provided certain steps are taken. For each straight C function which is to be linked into a C++ program, the C++ program must have a special external declaration. To properly link a C function from an existing library,
the C++ program must have the following extern symbol:
2.2 C++ Support for OO Programming
One of the major design goals for C++ was to support object-oriented programming. The strong compile-time typing of C++ adds complexity not found in pure object-oriented languages such as Smalltalk. The need to retain the efficiency and speed of C also influenced the support for OO programming. This section is organized around the fundamental concepts of object-oriented programming, describing how each is implemented in C++. A final section addresses some of the features of the language which allow a programmer to subvert the principles of OO programming.
2.2.1 Classes
The concept of class is the principal means of data encapsulation and abstraction in C++. You can think of a class as a structure with functions. In fact, in C++ struct is only a special case of class. The relation of class to object is that of a data type to a variable. A class consists of members: data and methods. Instance variables (sometimes abbreviated as "ivars") are the data members of a class. Functions and operators are the methods of a C++ class. This section will use a common convention for the names of instance variables, member functions, objects, and classes. Names are concatenated, descriptive words. In the case of classes, the first letter of each word is capitalized, like Employee, GraphNode, Animal. For ivars, functions, and objects the first letter of each word except the first word is capitalized, like printFirstName(), fedTaxWithholding, and newNode.
Consider representing an employee with a C++ class. Perhaps you are writing an application for a human resources department. You encapsulate everything you need to know about employees in this class with instance variables. The declaration of a simple employee class might look like this:
Classes differ from C structs by also having methods. These member functions and operators define what an object of this class can do, whereas the data members define what the object knows. Suppose an employee object can do three things: tell you its id number, calculate its length of service, and print its name in a company standard format. We can declare this functionality in our Employee class like this:
The definition of the member functions is usually in a separate source code file (an implementation file, e.g. Employee.cc) whereas the declaration for a class is in a header file (an interface file, e.g. Employee.h). The convention of separating the implementation from the interface promotes the sharing and re-use of classes.
The implementation file for the Employee class would have three functions defined in it, and would include the class header file, as well as any other header files needed for the function implementations.
The member functions of a class have full access to the instance variables of that class. The scope operator symbol, ::, is used to identify a function as a member function of a particular class.
Access to the members (both data and functions) of a class can be controlled. The keywords public, protected, and private are used to control access to the members of a class. Private members are limited to access by the member functions of the class. They are hidden from the outside world. Public members represent the interface offered to the outside world by this class. Protected members are accessible to the class itself and subclasses of the class. To achieve true data encapsulation, no data members should be in the public interface of a class. Instead, the public interface is composed of those functions which users of the class may ask objects of this class to perform. The public functions may themselves access private data members, but the details of this knowledge remain hidden from outside the class.
Here is a more OO declaration of our simple Employee class:
Protected access is described more fully in the section on inheritance.
C++ supports class members (i.e. data and methods shared by all objects of the same class) through the static modifier. For example, declaring a static int count variable in the private portion of the Employee class would result in all Employee objects sharing a single integer variable called count. This is in contrast to instance variables, where each object has its own personal copy. A static data member provides a means of having a "class global" variable while preserving data encapsulation.
A member function may also be declared static and be shared by all instances of a class, providing that the function only accesses static data members of the class, and not regular ivars or regular member functions.
A C++ class declared in a header file is defined the first time the header file is seen by the compiler. One common problem with placing class declaration/definitions in a header file is that there are situations in which it is easy to have multiple inclusions of the same header file. This results in multiple definitions for that class. For example, suppose you have a Circle class and a Square class, which are both subclasses of Shape. In a particular source file, say main.c, you are using both Circle and Square objects, so you #include Circle.h and Square.h. But each of those header files #include Shape.h, since they are subclasses of Shape. Now, in your source file, you have multiple inclusions of Shape.h, via Circle.h and Square.h. Figure 1 illustrates the problem of #including Shape.h twice, and hence the compiler trying to define class Shape twice.
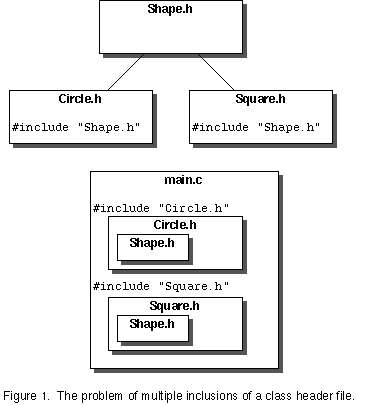
There are various solutions to this problem, but a commonly used one in the C++ world is to use the pre-processor directive which allows for conditional compilation. A macro is reserved for each class header file. If this macro has not yet been defined, the class declaration is included, otherwise it is not. The reserved macro is defined the first time the class declaration is included. Here's what the header file for the Shape class would look like using this approach:
2.2.2 Objects
Classes play the role of data type to objects. Classes are passive; they don't get your work done. By contrast, objects are active. An object definition causes the allocation of memory by the compiler. An object is instantiated from, or is an instance of, its class. Objects get your work done.
Objects get work done by messaging each other. Each message has at least two components: a receiver and a method. The method must be a member of the receiver's class definition. The optional third component of a message is the set of parameters required by the method being invoked. The messaging operators in C++ are identical to the structure access operators (. and ->) in C. The general form is:
Objects, like their built-in cousins ints, chars, and floats, may be created statically, at compile-time, or dynamically, at run-time, using the new operator.
C++ objects are passed by value to functions, and returned by value from functions by default. They may also be passed and returned by reference, or by address, as a pointer.
Objects with external scope (those defined outside of any function, or globally) have a lifetime which is the same as the process itself. Statically defined objects which are local to a function (automatics) have a lifetime corresponding to the duration of the scope of the function. They are created, like all automatic variables, upon entry to the function, and they are destroyed upon the functions return. By contrast, the lifetime of a dynamically allocated object is entirely up to the programmer. An object allocated from the free store by the new operator will exist until it is explicitly destroyed with the delete operator. The management of object lifetimes is a central part of the correct and robust solution to a problem in an OO paradigm. In C++ it is also the potential source of many problems and weaknesses of design.
When an object is created, a special member function, known as a constructor, is invoked automatically. The constructor function is responsible for the correct initialization of the object being created. Constructors, like any function in C++, may be overloaded to provide multiple interfaces for the creation of objects. All constructors for a class are given the name of the class. We could add a constructor declaration to our Employee class by putting the following lines in the public section of the class declaration:
This new declaration of our Employee class shows the constructors, providing three distinct interfaces for creating Employee objects, additional methods (known as accessor or get/set methods) for accessing the instance variables of the class, and a const keyword following certain class functions. The const keyword is applied to functions which are safe to perform with const Employee objects. These functions are guaranteed not to alter the instance variables of the object.
The three constructors can be distinguished by their parameter list. In the first case, no values are passed with which to initialize the object. In the second case, the employee id could be initialized from the integer argument. The last case provides values for employee id and name. Using the ability of C++ to specify default values for function parameters, these three constructors could be replaced by a single constructor which provides default values for id, first name and last name. The declaration of this single constructor would like:
An Employee object which was created with no arguments would have an employee id of 0, no first and no last name. We could implement this rather flexible constructor in the following way:
This constructor demonstrates the access to instance variables that member functions of a class have; it directly sets empId. It also shows a typical memory management issue faced in classes. The constructor dynamically allocates enough character storage to hold the names to which the object's ivars are being initialized. In a production class it would be more likely to see the details of character array allocation, and the char* ivars replaced by String objects.
A special type of constructor is generated automatically by the C++ compiler. The compiler-provided default copy constructor does a member-by-member copy of the instance variables. The copy constructor is used when an object is passed by value, returned by value, or initialized with another object of the same class through assignment. The prototype for the copy constructor for Employee would look like this:
and the implementation might be:
The copy constructor copies the values of the ivars from the parameter object into its own ivars. Here are some examples when each type of constructor is invoked, as well as the equivalent values for the parameters:
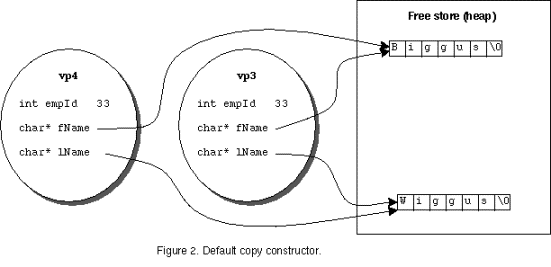
To understand the importance of writing a custom copy constructor for the Employee class, rather than just rely on the default implementation provided by the compiler, consider the effect of doing a member-by-member copy on the ivars of the Employee class. For empId there would be no problem, simply copying the ivar by value is sufficient. However, copying the char* fName and lName by value would mean that object vp4 would have pointers to the same character arrays as vp3. If vp3 were deleted, then vp4's fName and lName ivars would point to reclaimed memory. Figure 2 illustrates the result of the default copy constructor.
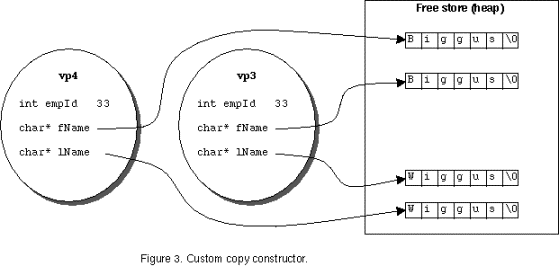
The custom copy constructor illustrated above correctly allocates storage for the name of the employee and then initializes this space from the object passed by reference as a parameter to the constructor. This is illustrated in Figure 3.
If a constructor is concerned about the beginning of an object's life, then a destructor is concerned about its death. A destructor function of a class is invoked whenever a dynamically allocated object is being deleted, or when a statically allocated object is going out of scope. The name of the constructor function is the name of the class preceded by a tilde.
The Employee destructor is responsible for deleting the storage allocated by the creation of an Employee object for first and last names. Without these delete [] operator calls in the destructor, the Employee class would have a memory leak, as the character arrays that were allocated in the constructor would not be returned to the free store, but would be lost to the program. Earlier in the discussion on new and delete it was stated that delete should be used with new, and delete [] with new[]. The reason should now be apparent; the destructor of a class should be called for each object in an array of objects. The delete [] operator makes sure this happens, whereas using delete on an array will only invoke the destructor for the first element of the array.
Objects may refer to themselves with the special variable, this. The this pointer is available in every class member function, and refers to the particular object executing the member function. The type of the this variable for an object of class X is pointer-to-X. One use of the this pointer is as a return value for class member functions. Returning the contents of this allows for class functions to be nested. For example, if a class to represent geometric shapes that are drawn in a window had a function move,
and a function display,
then a Shape object, s1, could be sent consecutive messages to move and display like this:
or it could be written in a nested fashion, like this:
The this pointer is also commonly used where memory management issues arise, as in adding elements to or removing elements from linked lists.
2.2.3 Inheritance
One of the most distinguishing means of representing relationships between abstractions in an OO program is with inheritance. Inheritance means forming subclass/superclass relationships between classes, also known as a base class and derived class relationship. A subclass inherits members from its superclass. Many classes together form an inheritance, or a class, hierarchy. Classes at the top of a hierarchy represent the data and functionality common between the classes which inherit from them. Classes at the top tend to be more abstract; objects are usually not instantiated from such classes. Classes at the bottom of the hierarchy are more concrete, and are more likely to be instantiated into objects. Classes which inherit from only one superclass exhibit single inheritance. Classes which inherit from more than one superclass exhibit multiple inheritance. Rich language that it is, C++ supports both single and multiple inheritance.
Continuing with our Employee class example, suppose that you needed to represent a variety of people in your programs, and not simply employees. You might have a Customer class, for example. Both customers and employees are people; the commonality between Employee and Customer class can be pushed upwards to an abstract Person class. Employee and Customer can inherit functionality and data from Person, rather than each having to define it themselves.
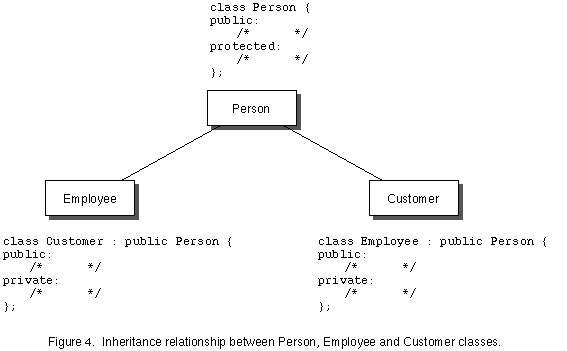
Figure 4 illustrates the base relationship that Person has to the derived classes Customer and Employee. The skeleton of the class declarations shows the syntax for indicating the base class in a derived class declaration. Since both employees and customers have names, the data members fName and lName of the Employee class could be removed from Employee and put instead in Person. The member functions to get/set these ivars would also be placed in Person. Objects instantiated from Employee and Customer inherit the data (names) from Person, and the ability to get/set those names. Consider the issue of access control to the fName and lName ivars in Person. They should be hidden from outside member functions to preserve data encapsulation. With the Employee class we achieved this level of protection by declaring them private. If we declare them private in Person, however, then objects of type Employee and Customer won't be able to use those ivars. The derived classes don't inherit the private members of the base class. The compiler will detect illegal uses of private ivars in derived classes. The solution to this problem is to declare fName and lName as protected. Protected members are public to derived classes, but private to the rest of the world.
Separate from the issue of access control for individual class members just discussed is the issue of how a derived class inherits from a base class. Inheritance may be either public, protected or private. Table 1 summarizes the possibilities from the perspective of the derived class. Public inheritance means that the public and protected members of the base class retain their status for the derived class. Protected inheritance from a base class means that public and private members of the base class are protected in the derived class. Private inheritance means that public and protected members of the base class are private in the derived class. Private inheritance can be used to insure that a public interface inherited from a base class is not available (i.e. not public) to the users of the derived class. Or, put another way, the fact that the derived class uses the base class via inheritance is hidden from the world by the derived class.
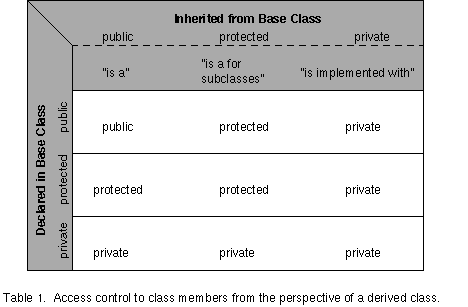
Meyers says the single most important thing to know about inheritance in C++ is that public inheritance means "isa". A derived class "isa" base class (and hence should publicly inherit from the base) if everything that is true about the base class is also true about the derived class. For example, a Dog class "isa" Animal, and everything that holds true for Animals is true for Dogs. The reverse, that everything that holds true of Dogs is true of Animals, is not true, and is equally important in the "isa" relationship. Derived classes which publicly inherit from their base classes reflect a specialization over the general base class.
Other relationships which are confused with "isa" include the "has a" relationship, which expresses the idea that a class is composed of another class. For example,the Employee class should contain a data member of class String to represent the name of the employee. We would say that Employee "has a" String. Another point of confusion in OO design often translated into implementation is the "implemented with" relationship. A class that merely wants to re-use the implementation of another class, for example, a Stack class using an Array class, may either include the useful class as a data member (composition), or it may use private inheritance.
The inheritance of member functions can be controlled to a finer degree of granularity than that of data members. A function in a base class may be of three classifications, normal, virtual, and pure virtual. The way to understand the distinction of these classifications is to separate the inheritance of interface from the inheritance of implementation. The data in Table 2 summarizes the use of these inheritance classifications. Normal functions are those which are neither declared virtual, nor pure virtual. Such functions specify an interface which is inherited by derived classes, as well as a mandatory implementation for the function. While a derived class may in fact implement its own version of such a function, and the scope operator can be used to access the base class function within the derived class, doing so violates the spirit of public inheritance as representing an "isa" relationship. When a derived class overrides a function from the base class by re-implementing it, the derived class is in effect saying that what is true for the base class (the function in dispute) is not true for the derived class, and needs to be implemented differently. This represents an exception to the generalization/specialization relationship between the base and derived classes. On a very practical note, the next section on messaging and polymorphism discusses a very confusing behavior of C++ related to this issue of the inheritance of normal functions.
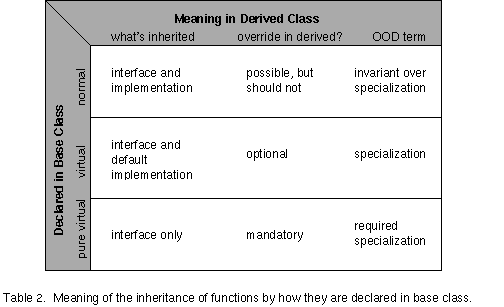
Virtual functions are made so by prefacing their declaration within a base class by the keyword virtual. These functions are designed to be implemented by a derived class in a way meaningful to the derived class (i.e. a specialization over the general base class). A virtual function may optionally have an implementation in the base class. If so, and if the derived class does not implement this function, then the implementation in the base class serves as a default implementation for the derived class.
A pure virtual function is declared by "initializing" the function in the base class declaration with the value 0. In order to derive a class from a base class with a pure virtual function, the derived class must implement the inherited pure virtual function. The example below illustrates the possibilities of function inheritance.
The function Base::fundamental() should not be re-implemented in Derived. The function Base::depends() may or may not be. If it is not, and if Base defines it, that implementation will serve for Derived. The function Derived::mandatory() _must_ must be implemented in order for Derived to inherit from Base.
As an example of the possible uses of function inheritance, consider the possibilities faced when Employee was generalized to Person, and the ivars which hold the name of an employee were moved to this more abstract class. What should become of the function Employee::printInfo()?
In Employee this function printed the employee id, then the first and last names of the employee object. Migrating the functionality for printing names up the class hierarchy offers two advantages: this code need not be re-implemented in Customer, and every Customer and Employee object would print their name in a single, standard fashion. If the means of printing names were indeed rigorously standardized, then Employee::printInfo() could be taken apart and become a new, non-virtual function Person::printName(). By being non-virtual, every derived class of Person would inherit not only the ability to print names, but a mandatory, standardized manner of doing it. The new Employee::printInfo() and the Person::printName() functions would look like this:
The scope qualifier of Person:: is unnecessary in the printInfo function, since Employee only has one version of this function, but it serves to point out exactly how an Employee object goes about printing its information.
As a design alternative, consider that since the printing of names may be highly context dependent, it might be better to allow the subclasses of Person to override this functionality. In this case Person::printName() would be more appropriate as a virtual function.
If the designer of Employee chose to implement a printName() function as above, then this function would be used on Employee objects, unless an explicit scope qualifier forced use of the inherited function. If no printName() function were implemented in Employee, then the default behavior, inherited from Person, would be used on Employee objects.
Inheritance complicates the initialization of objects. When an Employee object is allocated the constructors for both Employee and Person must be invoked, since the Employee object has instance variables from both Employee and Person. The syntax for doing this is:
The name of the base class is placed in the initialization list of the derived class constructor. Parameters to the constructor may be passed to the base class constructor as shown. Constructors in a multilevel class hierarchy are executed from the top of the hierarchy down. In this case the constructor for Person will execute before the constructor for Employee.
2.2.4 Polymorphism
Polymorphism is the idea that the code which is executed when a message is sent to an object depends on both the receiver's class and the name of the method in the message. In traditional procedural languages, the code which is executed by a function call is uniquely determined by the name of the function.
Before the idea of virtual functions was adopted, support for polymorphism in C++ was limited by the static binding that is done for non-virtual functions. Static binding results in faster executing programs, since the alternative, dynamic binding, leaves the decision about what code is actually executed when a message is sent to be determined at run-time. The drawback of static binding is that it violates the idea of polymorphism, that the code executed should depend on the receiver's class. When the receiver's class isn't known at compile-time, a static binding can't be made, and hence true polymorphism isn't possible. Why would the class of a receiver not be known at compile-time? When an object is dynamically allocated, and messaged via a pointer to the object. The classic example of this is a List class. Consider the graphics class hierarchy in Figure 5:
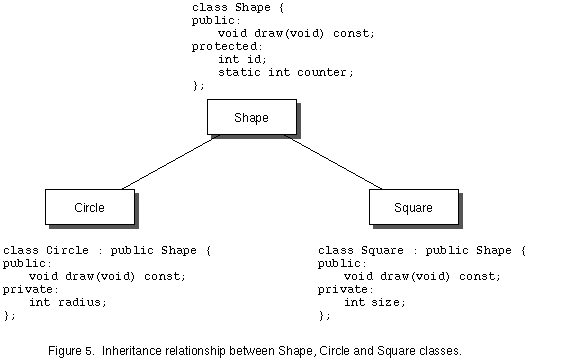
Each class derived from Shape must implement a draw function to display itself. Clearly, how a shape is drawn is quite class dependent, and so must be implemented in the subclasses of Shape. We can now do things like:
and see polymorphism in action as each figure correctly draws itself.
Now suppose you needed to message the Circle or Square object via a pointer. For example:
and polymorphism is still working for us. But what if you needed to message Circles and Squares, via the same pointer? For example, if you had a List class which was able to store heterogeneous objects, then you could walk through this list asking each object to draw itself. But what pointer type would you use? Since both Circle and Square are subclasses of Shape, we can address objects of both these classes via a pointer to their superclass Shape:
The problem is that the compiler statically binds the Shape::draw() method to the above two messages, based on the data type of the pointer. Having to worry about which actual function will be executed depending on which way an object is messaged doesn't seem very object-oriented. The solution to this problem is to declare the Shape::draw() function virtual. This defers the binding of the code to the message until run-time. With only a slight run-time penalty, the correct draw function is executed each time, whether or not the message is sent through a pointer, or to the name of the object.
We are now in a position to explain the earlier advice concerning overriding non-virtual functions of base classes. Since the binding of non-virtual functions is done statically, at compile-time, the actual function which will execute, that is the base or derived class function, depends on how the message is sent. If it is sent to an object of the derived class directly, or through a pointer to the derived class, the derived class function will execute. But if it sent to an object of the derived class, via a pointer to the base class, the base class function will execute.
A very common instance of needing to message objects of diverse types via a pointer is when you have a heterogeneous container class. As an example of a heterogeneous container class, consider a List class which holds pointers to Square and Circle objects, with an instance of a List class, docShapes, which is a list of all the shapes currently known to the program. The List class could store pointers to void, and a type cast could be performed to message the contents of the List. Suppose you want to ask each of these objects to draw themselves (as you might, for example, to refresh the window in a drawing tool). The following code seems plausible:
At compile-time the object which is being messaged with the draw() method has type pointer to Shape, the compiler therefore statically binds the code Shape::draw() for these messages. The result is that the individual Circle and Square objects don't draw themselves, but rather execute the default implementation of draw() which they inherit from Shape. Making the Shape::draw() function virtual solves the problem. Type casting is generally frowned upon in C++. Scott Meyers puts it this way: "Casts are to C++ programmers what the apple was to Eve". Meyers describes several means of eliminating type casts, depending on the problem the cast is used to solve.
Virtual functions provide dynamic binding, and hence complete polymorphism, only for classes which share a common base class. In the example above, it was only possible to message a Circle object and a Square object via a Shape pointer because Circle and Square derived from Shape. Virtual functions do not allow a message to be sent to every object in a general heterogeneous list of objects.
One final note about the Shape class concerns the static data member, count. If each object of classes derived from Shape were to have a unique integer identity, then it makes sense to have the Shape class manage this information. Each time a Circle or a Square are instantiated, the constructor for Shape will be invoked. By simply incrementing a counter stored in the Shape class, and assigning this counter to the id of the object being created, we guarantee that each object will have a unique identity.
Operator overloading for user-defined classes is another means of support for polymorphism in C++. The traditional C operators, such as =, +, -, /, *, [], <, == may be overloaded and defined for a class. Class operators are declared and implemented in the same way that member functions are declared; the syntax is a bit less traditional.
The above incomplete declaration of a String class shows two overloaded operators, += to concatenate and == to test for equality. The implementation of these operators would perform the necessary steps (perhaps using the C library) for adding one string to another (+=) and comparing two strings for equality (==). We could now use these operators like this:
Almost all existing operators may be overloaded. New operators cannot be made up. Operators new and delete may be overloaded for a class which wishes to manage its own memory.
2.2.5 Defeating OO Principles
One aspect of the richness of C++ is the ability to support more than simply the OO paradigm of software development. Coupled with the desire to make C++ fast and efficient, several language features were created which can be (mis-)used in the implementation of an OO design. Experienced C++ programmers learn to make judicious and profitable use of these features. Novice C++ programmers often make a mess with them.
Free functions are functions which are defined outside the scope of any class. They may be used by class member functions. Library functions are examples of free functions in C++. Looking in the index of a C++ textbook won't usually turn up anything under free function, since a free function is simply a normal function in C. In the purer world of object-oriented thinking, where "everything's an object", free functions stand out.
If free functions are only passively un-OO, friend functions are actively so. A free function may be declared to be a "friend" to a class in the declaration of that class. Doing this grants access to the non-public parts of the class to the friend function. Throwing data hiding in the trash shouldn't be done lightly, but there are times when breaking the rules can be enormously handy. Friend status may also be granted to other classes.
Support for global data (i.e. objects with global scope) is similar in C++ and C. The use of global data should be similarly limited. Complications arise when global objects are initialized with other global objects, particularly if the objects are in different files. Refer to a good book on C++ if you need to do this. Meyers has a lengthy discussion on this topic.
Data members in the public interface of a class subverts the data hiding intent of encapsulation. Access to data members should be controlled by member functions in the public interface.
2.2.6 Advanced Features
The nature and length of this chapter precludes an exhaustive description of C++. A non-scientific sampling of the length of C++ books reveals page counts of 660, 670, 980, and 420. While the features of the language discussed in this section are of vital importance to flexible and robust C++ class design and use, their complete description must be left to other references. These features are also likely to vary greatly between compilers.
Exception Handling
Despite the best efforts of the C++ compiler to enforce strong typing with compile-time checking and static binding, run-time errors can still occur. These include misuse of user defined classes (e.g. giving an Employee a negative id), operating system limitations (e.g. running out of free store), and mathematical operations like dividing by zero. C++ refers to these sorts of events as exceptions. The verb "to throw" is used to describe the event of raising an exception. The exception handling facility of C++ allows the programmer to "catch" exceptions, execute a block of code, and exit. To be caught the exception must be thrown in a try block, or in a function called directly or indirectly within a try block. Try blocks are associated with one or more catch blocks. The following example shows throwing an exception when the free store has been exhausted:
Upon being thrown, control flow is transferred to the appropriate catch block, if any. After executing the catch block, control flow does not return to the point of the exception throw.
Templates
Templates allow you to parameterize a class by type. A good way to judge whether a template is an appropriate solution to defining a new class (versus subclassing an existing class, for instance) is by whether or not the semantics of the class depend on the type of data being operated on. If the semantics of the class are independent of the type of data, then a template is a good choice.
A classic example of use of a template is the Stack class. Suppose you have already written an IntegerStack class, implementing push and pop functions, and constructors and destructors for the class. Your IntegerStack class is written to handle integers; it is completely type safe, and so can’t be used for other data types. If you eventually need a FloatStack class, you have two choices: you can try to create a generic Stack base class, from which both IntegerStack and FloatStack inherit, or you can make a template class of Stack. A Stack template will allow you to create, as needed, Stack classes for any data type. The operations of the stack are entirely independent of the type of data being manipulated.
Here’s the declaration for the interface of a template Stack class which implements a stack as a linked list of StackElement objects. The StackElement class is defined within the Stack class (StackElement is nested within Stack):
And the skeleton implementation of the template Stack class would look like:
In order to use the Stack template, a type must be provided to instantiate the Stack class for a particular type of Stack, for example:
Multiple Inheritance
The necessity of multiple inheritance (MI) is widely disputed. The advantage of multiple inheritance is that a class hierarchy can be constructed which more closely resembles the domain being modeled. Some OO languages support it, others do not. C++ offers multiple inheritance.
Detractors of MI claim it is not necessary, and have other techniques for modeling what may be done with MI (e.g. delegation, forwarding, and protocols in Objective C). Whether or not MI is necessary, there is general agreement on the complexity of using MI. As Meyers puts it,
"The one indisputable fact about MI in C++ is that it opens up a Pandora’s box of complexities that simply do not exist under single inheritance." page 157.
Multiple inheritance should be avoided by novice C++ programmers. Experienced programmers should use MI judiciously, and should study the sections on MI in several texts closely before doing so.
RTTI
One of the most recent features of the C++ language is support for RTTI, or Run Time Type Information. This allows an object to introspect at run-time to determine its class. This sort of introspection is commonly used in more dynamic OO languages, such as Objective C and Smalltalk.
2.3 Defining C++ Terms
- base class: A class which is inherited from, or subclassed by another class.
- cin, cout, cerr: The I/O stream replacements for stdin, stdout, stderr.
- const: A modifier to make a data object constant
- constructor: An initialization function which is executed automatically when an object is created.
- delete: The equivalent of C's free. Returns dynamically allocated storage to the heap.
- derived class: A class that inherits from a base class.
- destructor: A function that is executed automatically when an object is deleted.
- inline: Asks compiler to avoid function call, place copy of function body directly at point of invocation.